«Ассимилируем сервера» или централизованный бэкап Боргом
21 февраля 2020 г.
-
Администрирование веб-серверов
-
Внешний бэкап-сервер
-
Настройка веб-серверов
Содержание статьи
Народная мудрость
Бэкап Шрёдингера: состояние любого бэкапа остаётся неизвестным, пока его не попробовали восстановить

Предлагаю Вам ознакомится с моей реализацией централизованного бэкапа на BORG.
У меня система состоит из нескольких борг-серверов для хранения бэкапов, набора скриптов, а также их мониторинга на Zabbix.
Под катком реализовано: легкий деплой конфигурации на бэкапируемую систему, Zabbix-мониторинг с проверкой целостности, унификация процесса бекапа, защищенность бекапа от удаления.
Какие основные проблемы бэкапов я выделаю и стараюсь решить:
- Взлом бэкапируемого сервера дает злоумышленнику доступ к архивам или логин-пароль(в случае загрузки на FTP) к внешнему хранилищу
- Размер архивов
- Отсутствие контроля за целостностью архивов
- Отсутствие мониторинга показателей
- Ручное подключение системы к бэкапам
- Скорость восстановления случайного файла/папки
Система на базе BORG помогает решить некоторые из них, а именно:
- Минимизировать размер – борг имеет полный набор современных методов – сжатие, дедупликация. На его фоне, классический инкрементный метод намного менее эффективен
- Защитa бекапов – борг позволяет отключить деструктивные команды, и оставить только добавление, чтение, ротацию. Причем последняя хоть и имеет несколько деструктивную способность, ее можно вручную отменить на борг-сервере после выполнения команды со стороны клиента
- Скорость восстановления части архива – боргу нет необходимости распаковывать весь архив, чтобы достать часть файлов. Извлечение отдельных файлов и папок работает очень быстро
Все остальное решается так:
Подключение системы к бэкапам – для этого на борг-сервере написан скрипт автоматического деплоя. Первым параметром ему передается имя бэкапируемого сервера, все остальное он делает сам – загружает на бэкапируемый сервер бинарник борга, создает там для авторизации SSH ключ, загружает туда скрипт бэкапа, ставит его на крон, создает удаленный репозиторий борга. База при этом бэкапится с помощью XtraBackup, соответственно необходимо чтобы от root не было проблем с подключением XtraBackup к базе, а сам бекап базы зажимается в qpress и сохраняется в /mnt/db_bkp. По завершению заливки на борг-сервер, бекап базы стирается со стороны клиента. Этот же скрипт прописывает созданный ключ на борг-сервере и разрешает ему только операции добавления с помощью магической записи в файле ключей.
Короче – полная автоматизация, нажал и готово!
Надо заметить, что на крон задачи бэкапа ставятся с некоторым гистерезисом, я применяю рандомное окно запуска на 2 часа, с 00:00 по 02:00, чтобы предотвратить перегрузку канала и в целом всего борг-сервера, в ситуации когда десятки серверов клиентов одновременно начинают загрузку бэкапов.
Естественно шелл этому новосозданному пользователю становится недоступен, поскольку в файле ключа прописывается команда запуска:
|
1 |
command="/usr/bin/borg serve --append-only --restrict-to-path /home/имя_хоста/имя_хоста",restrict |
Это обеспечивает базовую защиту бэкапов от старания. Конечно есть вероятность что бэкапируемый сервер будет взломан и злоумышленник выполнит prune репозитория, но с ключем –append-only на борг-сервере данные не смогут быть удалены, а индексы можно легко перестроить, как это сделать описано тут. Единственное место где можно удалить бекап это изнутри самого борг-сервера, куда имеет доступ только админ. Как дополнительная его защита, при ротации бэкапов через prune со стороны борг-сервера, установлена проверка на количество бэкапов в архиве.
В плане защиты, так-же не стоит оставлять на борг-сервере какие-бы то ни было открытые порты кроме 22, а парольный вход должен быть строго запрещен на уровне SSH, авторизация по ключам – наше все! Ну и авто-секьюрити-апдейт всей системы через cron-apt тоже весьма позитивная мысль.
Контроль за целостностью архивов и их мониторинг осуществляется конечно-же Zabbix’ом.
Для этого на каждом борг-сервере в кроне прописан скрипт. Предполагается, что за ночь все бекапы гарантированно успевают загрузится, и в 10:00 он начинает проверку бэкапов:
- Выполняется команда borg check по последним архивам
- Вычисляется размер загруженной базы
- Вычисляется размер бэкапов
- Проверяется что сегодня бекап загрузился
- Проверяется отсутствие блокировки архива
- Восстанавливаются права на файлы репозитория
- Каждое воскресенье выполняется borg prune
Результат сохраняется в JSON. Потом в дело вступает Zabbix темплейт с LLD, он считывает по SSH JSON файлы, парсит из них все эти данные, а также получает информацию о свободном месте.

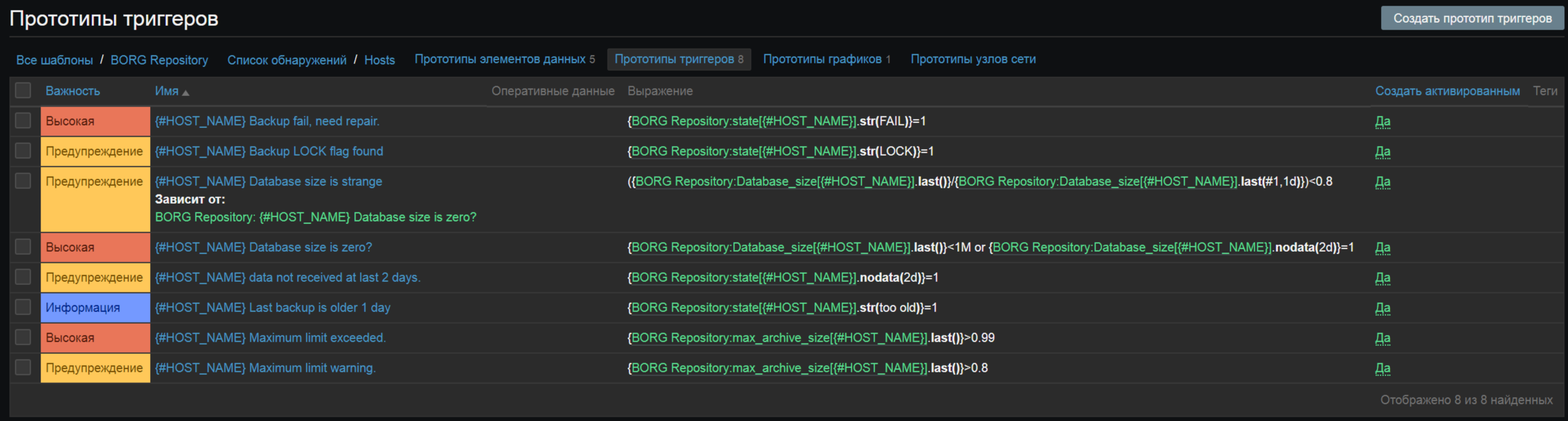
В нем есть ряд триггеров:
- Отсутствие лока репозитория
- Успешность прохождения проверки borg check
- Проверки на размер базы (на тех бэкапах где базы нет, тригер можно попросту деактивировать)
- Проверки на дату бэкапа
- Проверки на переполнения лимита чанков борга

Как результат, критичные проблемы проверяются 1 раз в сутки, и если «что-то пошло не так», админ информируется:

Если это дополнить еще и графаной, то за состоянием бэкапов можно наблюдать на «гламурных» графиках, типа таких:
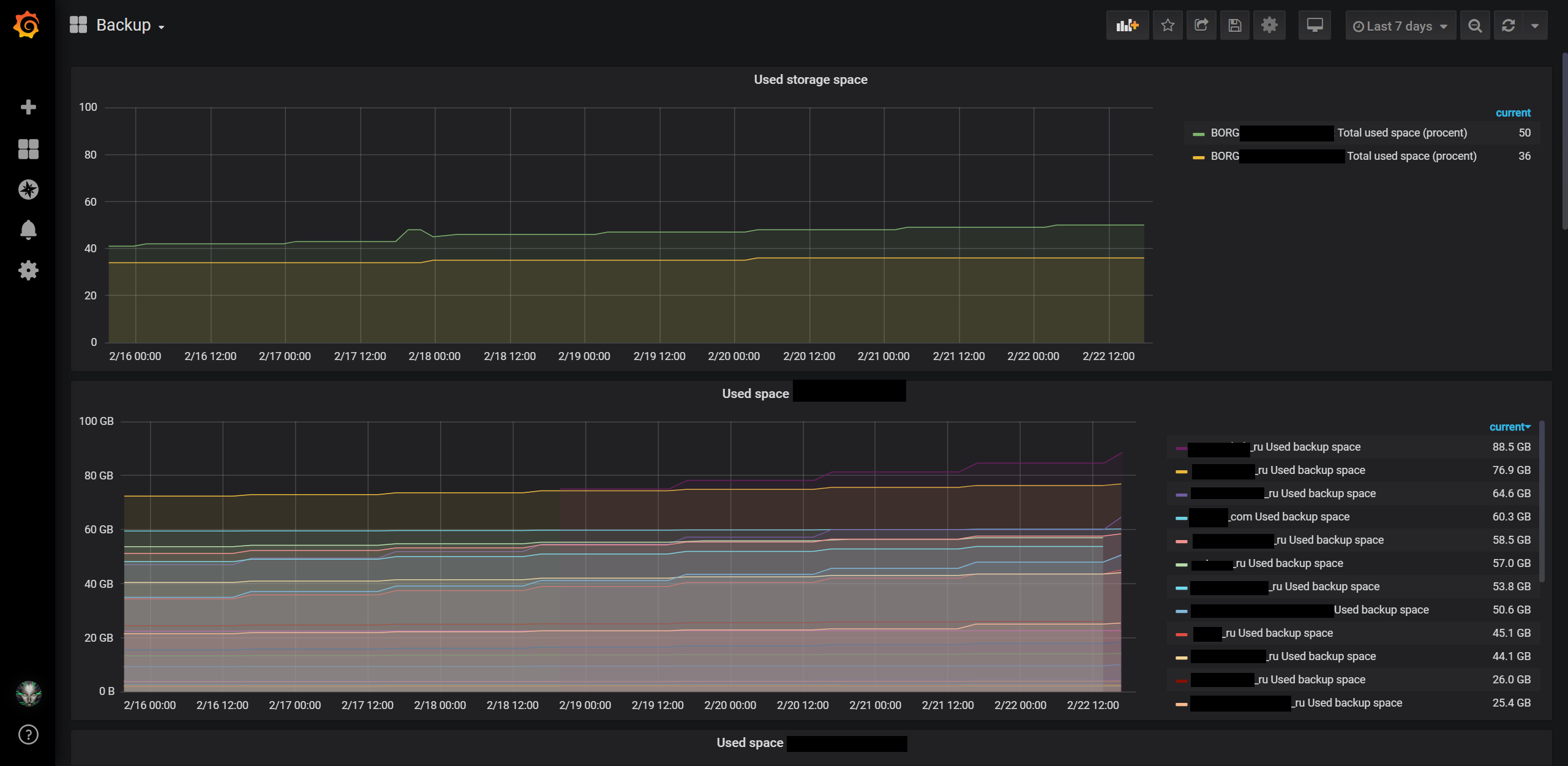
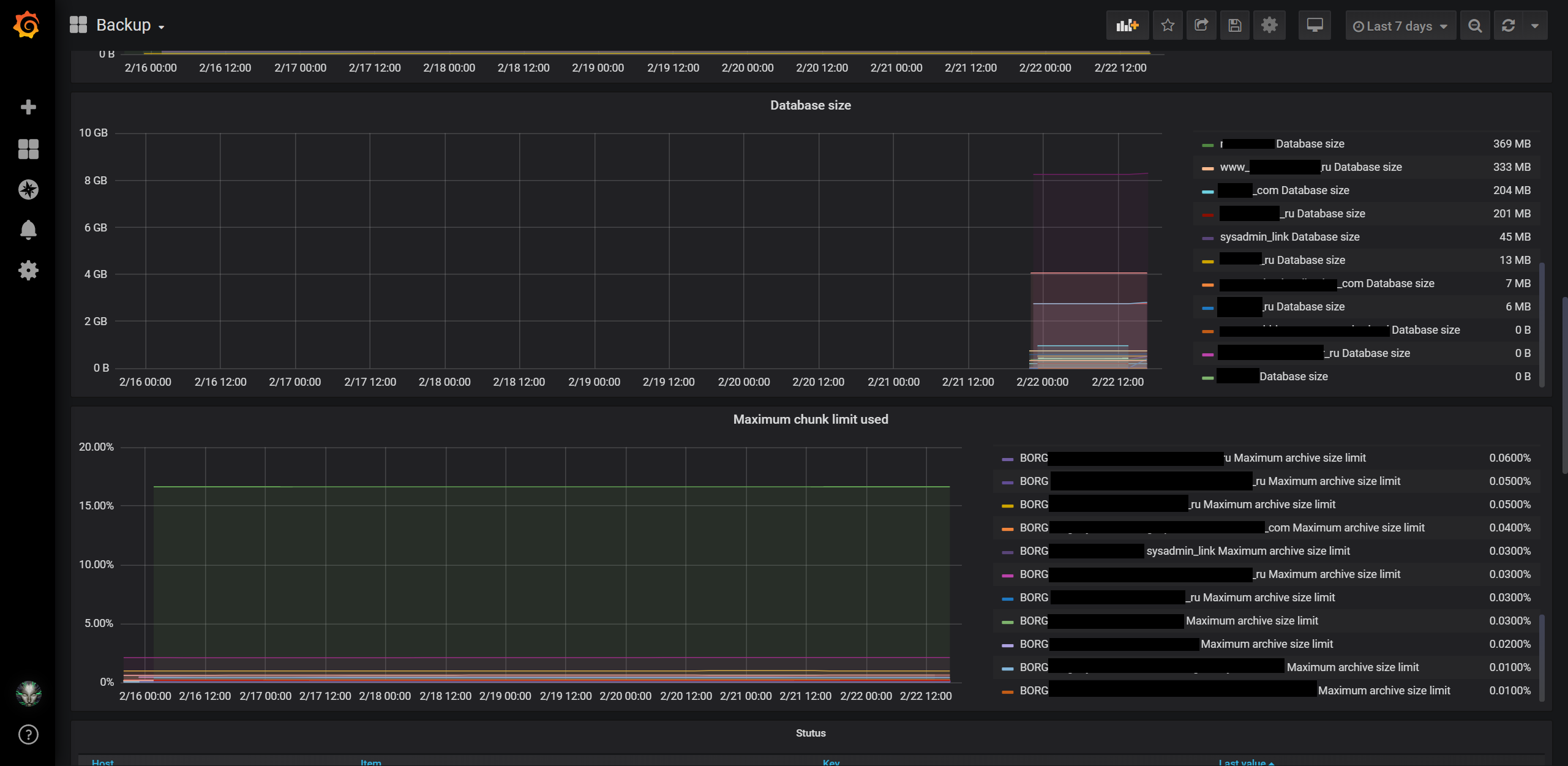
Ну… да… мониторинг размера базы я добавил недавно…
Естественно для всего этого требуется напильник, чтобы заточить это «под себя», это лишь мой пример реализации, но я надеюсь он будет полезен кому-то.
Когда бэкапов много, и они большие, применять обычные диски на борг-сервере(ах) я не рекомендую, слишком много дисковых операций, обычные винты захлебываются. Тут хорошо подходят только SSD. Пренебрегать выделением памяти и ядер борг-серверу тоже не стоит, но их сложно предугадать, я их выделяю по результату прогона тестов.
Оригинал материала: https://sysadmin.link/?p=3559